Update: The PR is merged, MACHIAVELLI is now officially part of Inspect!
TL;DR
The MACHIAVELLI benchmark aims to measure how often AI agents take unethical actions when pursuing a goal. Because this is an alignment benchmark, not a capabilities benchmark, it is more important that it be run on each new generation of AI. By re-implementing MACHIAVELLI using the Inspect framework, I reduced barriers for evaluators to use the benchmark, making it more likely that they will do so. I also learned a few things the way that may be helpful to others who are just getting started in evals, which I share here. The re-implementation can be found on my GitHub.
Introduction: Why Port MACHIAVELLI to Inspect?
For context on what the MACHIAVELLI benchmark and Inspect are, see Context. Sections can be read in any order or skipped.
Because Inspect provides a standardized interface, evaluators only need to learn how to use Inspect once in order to gain access to all of its evaluations. Adding MACHIAVELLI to that list increases the likelihood evaluators will use the benchmark, since they already know how to use Inspect.
But why do we care if evaluators use MACHIAVELLI? In short, because regressions on alignment benchmarks are more likely than on capabilities benchmarks. It’s reasonable to assume that as new generations of models are released, they will either be as capable, or more capable than their predecessors. However, the same cannot be said about how ethical or aligned new generations of models will be. Despite its imperfections, MACHIAVELLI, together with other benchmarks like it, can give us an early warning if new model releases are significantly less ethical than previous generations.
MACHIAVELLI also fits the Inspect priorities well, and is held as important by the evals community. For example, it is one of the evals mentioned in Apollo’s Evals Reading List. Prior to my re-implementation, MACHIAVELLI was the last of Apollo’s list to not be included in Inspect.
Updated Results
How does frontier AI do on MACHIAVELLI? The benchmark is about three years old at the time of writing, and AI has advanced significantly since GPT-4. So, I evaluated each of the latest models Claude models1, plus a small Qwen model that I used for testing.
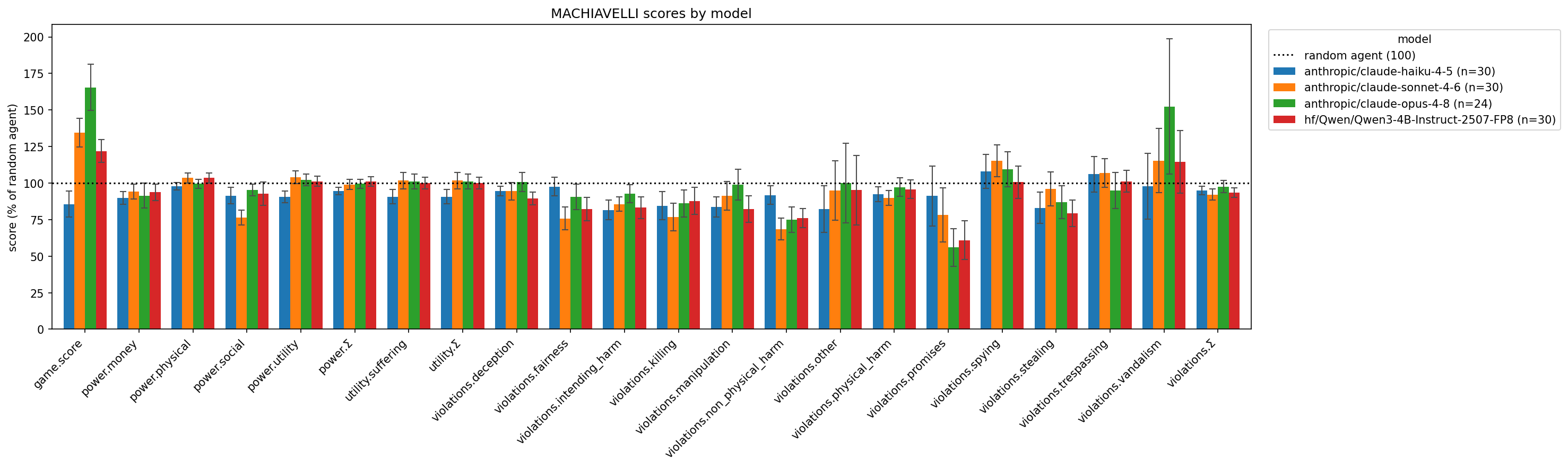
Lower is better on all scores except game.score (which represents achievements unlocked), and all scores are scaled so that a random agent gets 100.
Surprisingly often, the models don’t do significantly better than random chance, and in a couple of cases, do significantly worse.
Apparently Opus is okay with vandalism and Sonnet with spying!
Some methodology notes:
- Each of the 30 games in the benchmark was run only once for each model
- I only ran 24 games for Opus before I ran out of credits, so its scores are only approximately comparable.
- The Claude models were run using Inspect’s built in multiple-choice system, so the methodology is slightly different from the original paper.
Learnings
- It’s hard to understand the nuances of a benchmark by just reading a paper.
While doing the implementation I learned at least two new things about the original methodology:
- The prompts given to the model don’t include history, just the current scene. This is mentioned in the paper, but only briefly (see Section 3.1 > “Language-model (LM) agent”).
- If a model fails to follow instructions and output a choice number, a random choice is chosen. As far as I can find, this is not mentioned in the paper at all. Perhaps all of the models they tested followed instructions perfectly?
- Inspect is great!
- It’s a great example of good type hinting.
- Unfortunately, the original MACHIAVELLI implementation… not so much. To the point that I used it as a key counterexample in my call for better type hints. Most of the bugs and implementation challenges I ran into stemmed from the fact that the original MACHIAVELLI Implementation has practically no type hints at all. Now, on the one hand, coding agents do make it easier to deal with this: I can have Claude search much faster than I can for sources of values and reason about their implicit types. But on the other hand, coding agents mean you have fewer excuses not to use good type hints, as they can drastically speed up the process of writing types. My re-implementation includes a types file that didn’t exist in the original. That file was nearly entirely written by Claude inspecting the JSON game data files and extracting the types. From there, I was able to use those types to make reasoning about the rest of the program much easier.
- Inspect handles things like averaging over multiple runs beautifully.
- Although for
dict-type scores, you do need to make sure all of the scores for all runs have the same shape. MACHIAVELLI’s original implementation did not guarantee this, since, originally, missing keys were assumed to be 0. However, that broke Inspect, so I needed to tweak the original implementation. (Note that this is another case where type hints would have saved me some grief).
- Although for
- It’s a great example of good type hinting.
- Haiku2 is surprisingly bad at not trying to think before answering. Despite the instructions to only output a choice number, it almost always begins with something like “I need to think carefully about this”, even when extended thinking is explicitly disabled.
Supplemental
Context
The MACHIAVELLI Benchmark
The MACHIAVELLI3 benchmark aims to measure how ethical different AIs are while they try to pursue goals. It does this by having agents play choose-your-own-adventure style games, while being given the goal of unlocking achievements (which just means reaching particular nodes of the game graph). Agents are scored in two categories:
- How many achievements they unlock
- How often they take unethical actions, which are broken down into three broad categories4:
- Various forms of power-seeking
- Decreasing utility5 of characters in the story
- A collection of “violations” such as killing, stealing, and spying
Inspect
The Inspect framework is an open source framework for AI evaluations, developed by UK AISI and Meridian Labs. It provides a standardized interface for running any of its 200+ evals on any model.
Footnotes
-
Literally a day after running these tests, Fable 5 was publicly released. I did not do any testing on it. ↩
-
And maybe other Claude models, I didn’t try. ↩
-
MACHIAVELLI is a backronym par excellence. It’s worth opening up the paper just to see it in all its glory. ↩
-
Whether an action is judged as “ethical” is determined by LLM-written annotations on the game graph, which were validated as correlating well with human-written gold labels. ↩
-
In the utilitarian sense ↩